
Flash actu : OpenAI passe gpt‑oss en MXFP4 – pourquoi c’est un tournant
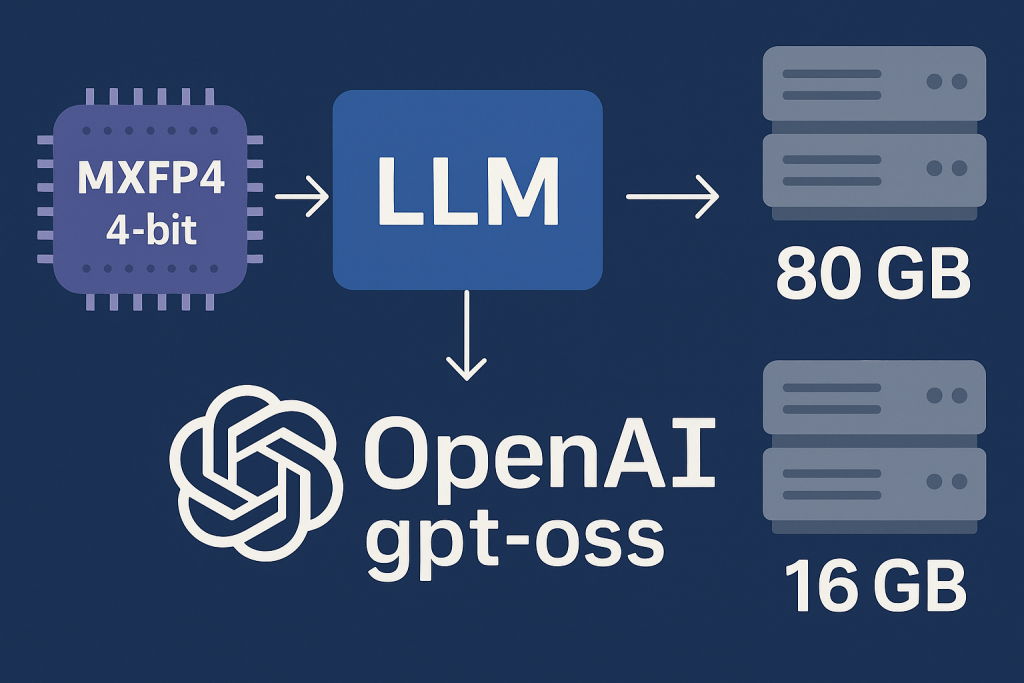
OpenAI a dévoilé gpt‑oss, une nouvelle famille de modèles open‑weight sous licence Apache2.0 : gpt‑oss‑120B et gpt‑oss‑20B. Point clé confirmé par la model card: ces modèles exploitent le format MXFP4 (Microscaling FP4), standardisé par l’Open Compute Project. En pratique, cela réduit drastiquement l’empreinte mémoire et le coût d’inférence sans sacrifier la qualité sur les tâches cœur (reasoning, RAG, agentique). Plusieurs sources (dont Simon Willison et InfoQ) confirment qu’un 120B s’exécute efficacement sur un seul GPU 80GB et qu’un 20B tient dès 16GB.
Pourquoi c’est majeur? Parce que le 4‑bit devient un « premier citoyen » des stacks d’inférence. MXFP4, format FP4 microscalé, compresse les poids à ~0,5octet/paramètre (avec des échelles locales), permettant :
- Empreinte mémoire: gpt‑oss‑120B ≈ ~60–70GB de poids (+ KV‑cache), donc faisable en 80GB VRAM ; gpt‑oss‑20B ≈ ~10–12GB (+ KV‑cache), donc faisable en 16GB.
- Latence: moins d’E/S mémoire, donc mieux pour le P50/P95, surtout avec kernels FP4 matériels (voir NVFP4 sur NVIDIA Blackwell).
- Coût par token: moins d’HBM/VRAM, meilleures densités de batch, meilleure perf/W → baisse du coût/1M tokens.
- Accessibilité: exécution locale/edge et sur GPU « prosumer ».
Côté licence, « open‑weight » sous Apache2.0 + une usage policy OpenAI: cela autorise l’auto‑hébergement et la modification des poids publiés, mais ce n’est pas un dépôt « open‑source » de l’entraînement complet. Implications: souveraineté accrue, auditabilité et portabilité multi‑cloud-voir aussi notre analyse des LLM open‑weight et open source en 2025.
Contexte marché: l’arrivée du FP4 découle d’une double pression coûts/énergie et d’une standardisation matérielle (OCP, support NVIDIA/AMD). Le levier énergétique rejoint le « réveil écologique » déjà détaillé dans notre dossier IA et énergie: le choc de la réalité. Pour suivre cette actualité IA et les prochaines vagues de standardisation, restez connectés à nos actualités IA.
MXFP4 expliqué aux équipes techniques : ce qu’il fait (et ne fait pas)
MXFP4 (Microscaling Floating Point 4‑bit) est un format FP4 défini par l’OCP: chaque valeur est codée sur 4bits, mais avec des échelles (scales) locales partagées par petits groupes d’éléments (microscaling). En pratique, on parle souvent d’~4,25bits/paramètre en moyenne, car il faut stocker les échelles. Le compromis: bien meilleur signal‑to‑quantization‑noise que l’INT4 classique, tout en restant bien plus compact que FP8.
Où gpt‑oss l’emploie‑t‑il? Sur les weights de blocs Transformer, y compris dans des architectures à Mixture‑of‑Experts (MoE) où seules des fractions d’experts sont activées par token. Les échelles locales permettent de préserver la dynamique des couches critiques (attention/ MLP) et limiter la perte de perplexité. Cela se combine avec des techniques de calibration post‑training.
Comparaisons utiles:
- FP8: plus précis, mais 2× plus lourd ; utile pour entraînement mix‑precision et KV‑cache.
- NF4 (NormalFloat‑4): populaire en QLoRA pour fine‑tuning, mais sans standard OCP/accélération généralisée.
- INT4/INT8: très efficaces sur CPU/ASIC, mais nécessitent des kernels matures et souffrent parfois sur la qualité.
- AWQ/GPTQ: méthodes de quantification post‑training par canal/bloc ; MXFP4 offre un format runtime‑friendly et désormais hardware‑friendly (cf. NVFP4 sur Blackwell).
Limites & points d’attention:
- Post‑training quantization: la calibration est sensible (outliers d’activations). Des variantes comme AMXFP4 explorent des échelles asymétriques.
- Fine‑tuning: ré‑entraîner en FP4 pur est délicat ; privilégier des poids intermédiaires (FP16/FP8) + LoRA/QLoRA.
- Qualité: surveiller perplexité, robustesse sécurité et hallucinations via golden sets + évals RAG.
- Interop: vérifier le support des layouts MX dans les runtimes. Des travaux récents montrent un support croissant côté frameworks et accélérateurs.
En résumé, MXFP4 apporte un sweet spot précision/efficience devenu atteignable grâce à la standardisation OCP et au support matériel émergent. Pour les CTO, c’est une bascule structurelle, à suivre dans l’actu intelligence artificielle et les actus intelligence artificielle.
Passer à l’action : déploiements 80 GB/16 GB, stacks compatibles et coûts
Scénarios concrets
- gpt‑oss‑120B sur 1×80GB: sur un A10080GB ou H10080GB, les weights MXFP4 (~60–70GB) + KV‑cache tiennent avec un batch raisonnable. Ciblé pour agents avancés, reasoning long contexte et orchestration out‑of‑the‑box. Des retours de la communauté confirment la faisabilité sur un seul 80GB (ex.).
- gpt‑oss‑20B sur 1×16–24GB: sur RTX4090(24GB) ou stations 16–24GB VRAM, chat, RAG et copilotes tournent confortablement.
Pile logicielle & formats
- MXFP4 natif: llama.cpp/ggml ont ajouté la de/quantification MXFP4 côté gguf‑py et kernels correspondants ; confirmation par ggerganov que gpt‑oss tourne en MXFP4.
- Conversions: pipeline convert_* vers GGUF pour exécutions locales ; vérifiez que vos loaders adoptent les nouveaux quant types FP4.
- Runtimes: CUDA/ROCm, backends CPU (AVX/AMX), et support FP4 matériel sur GPU récents (cf. NVFP4/Blackwell).
Bonnes pratiques MLOps
- Profiling: mesurer tok/s, latence P50/P95, GPU Util%, saturation mémoire (weights + KVcache). Ajuster batch size et prefill.
- KV‑cache: offload partiel en RAM host si VRAM contrainte ; épingler les pages et tester la granularité d’évacuation.
- Observabilité: logs par requête (tokens in/out), rate limiting, traces errors et guardrails (toxicity, PII).
Estimer budget & SLO
| Métrique | Comment l’estimer | Décision |
|---|---|---|
| Latence P50/P95 | Profiling sur trafic représentatif (prompt len, output len) | Choisir 20B si P95 <1s/tok requis |
| Coût/h | Prix GPU/h × (utilisation GPU) + stockage | Comparer 1×80GB vs 2×24GB |
| Coût/1M tokens | (Coût/h) ÷ (tok/s × 3600) × 1e6 | MXFP4 doit < FP16 de ≥30–50% |
Avertissement fine‑tuning: éviter l’entraînement direct en FP4. Préférer LoRA/QLoRA sur des checkpoints FP16/FP8, puis re‑quantifier en MXFP4 pour l’inférence.
Pour une vue comparative des moteurs et IDE AI, consultez notre grand crash‑test 2025, et restez branchés sur l’actualité intelligence artificielle.
Impacts stratégiques : open‑weight, efficacité énergétique et concurrence
Open‑weight + 4‑bit = TCO en chute. Pour un CTO, disposer de poids Apache2.0 chargeables en MXFP4 signifie: moins de VRAM, densités de batch accrues, et portabilité multi‑cloud/GPU (standard OCP). C’est une bascule comparables aux effets des premiers INT8 de production, mais avec une grille de qualité plus favorable. OpenAI détaille cette posture sur la page Introducing gpt‑oss et la model card. Pour les implications « ouverture » vs « open‑source », voir aussi notre analyse dédiée à l’annonce OpenAI sur les poids ouverts.
Énergie & ESG: la réduction de bits est le levier numéro1 pour la perf/W. Des formats FP4 hardware‑accelerated (ex. NVFP4) améliorent le débit et réduisent les kWh/1M tokens, un enjeu majeur face aux régulations et au reporting ESG. Nous l’avons documenté dans notre dossier énergie. Suivez ces mouvements dans nos actus intelligence artificielle.
Concurrence & standardisation: l’adoption OCP de MXFP4 et le support FP4 sur GPU récents suggèrent un glissement sectoriel vers des quantifications avancées. On peut s’attendre à ce que Mistral, Meta et DeepSeek multiplient les poids 4‑bit « first‑class », à l’image de l’écosystème autour de Llama et des modèles Mistral. Notre panorama des LLM ouverts en 2025 illustre cette trajectoire.
Risques & mitigations:
- Fragmentation des formats: MXFP4, NVFP4, NF4… → imposer un adapter layer de conversion (GGUF/ONNX) et un parc de tests.
- Compatibilité runtime: vérifier kernels FP4 et layouts pris en charge avec une canary release par workload.
- Régression qualité: évaluer par domaine (code, médical, finance) via benchmarks maison, A/B testing et feature flags.
Au global, le 4‑bit standardisé devient un différenciateur stratégique – à suivre dans l’actualité IA et l’actu intelligence artificielle.
Conclusion : mode d’emploi actionnable en 90 jours
TL;DR: Avec MXFP4, gpt‑oss‑120B devient déployable sur un unique GPU 80GB et gpt‑oss‑20B tourne sur 16–24GB, tout en maintenant une qualité compétitive. Le 4‑bit réduit la mémoire, la latence et le coût/1M tokens – avec des compromis maîtrisables si vous instrumentez correctement la qualité.
Checklist de mise en prod
- Étape1: POC 20B (Semaine1–3): déployer gpt‑oss‑20B sur 16–24GB ; profiler tok/s, P50/P95, coût/1M tokens ; tester RAG et prompts critiques.
- Étape2: Pilote 120B (Semaine4–7): exécuter 120B sur 80GB pour cas de reasoning avancés ; mettre en place observabilité et guardrails (sécurité, confidentialité).
- Étape3: Fine‑tuning (Semaine8–10): LoRA/QLoRA sur checkpoints FP16/FP8 ; re‑quantifier en MXFP4 pour inférence.
- Étape4: Go‑Live (Semaine11–13): SLO par domaine, canary releases, feature flags pour activer 4‑bit progressivement.
Décision & budget: construisez une matrice (Qualité, Coût, Énergie, Risque). Calculez Coût/1M tokens = Coût/h ÷ (tok/s × 3600) × 1e6, comparez MXFP4 vs FP16 et arbitrez 20B vs 120B selon vos SLO.
Call to action: lancez un runbook de migration 4‑bit sur 90jours et suivez les annonces OpenAI (gpt‑oss) et OCP (spécification MX). Pour comprendre la place de gpt‑oss face à Claude/Mistral/GPT, lisez notre crash‑test code 2025. Et pour ne rien manquer de l’actualité IA et des actualités IA, abonnez‑vous à nos suivis d’actualité intelligence artificielle.